678娱乐场点击下图进入官网:

678娱乐场点击下图进入活动:

678娱乐场点击下图进入领取彩金:

现在什么游戏最好玩|http://xzsmyxzhwxnzg.weebly.com
太阳城娱乐菲律宾|http://tycylflbmfys.weebly.com
万博2.0客户端|http://wbkhdprhc.weebly.com
葡京网址|http://pjwzpzzt.weebly.com
齐乐娱乐官网|http://qlylgwpzxv.weebly.com
bet36体育在线|http://bettyzxmzyt.weebly.com
神经网络的深度(深层神经网络,以下简称DNN)是深的基础学习,并了解DNN,我们必须首先理解DNN的模型,我们的模型和DNN的向前传播算法做一个总结。
在中,我们介绍了感知器模型,这是一个输入和一个输出模型,如下图:
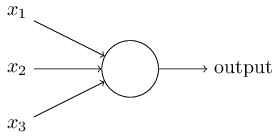
学习输出和输入之间的线性关系,中间输出结果得到:$ $ z = \ \ limits_总和{ I = 1 } ^ mw_ix_i b + $ $
紧随其后的是一个神经元激活函数:
$ $符号(z)=
开始\ {病例}
1 & z \组的{ 0 }
{ \结束案例} $ $
得到我们想要的输出1或1
这个模型只能用于二进制分类,不能学习更复杂的非线性模型,因此不能用于工业。
而神经网络感知器模型扩展,总结主要有三点:。
1)加入了隐层,隐层可以有多层,提高模型的表达能力,下面的图表为例,增加这么多隐层模型的复杂性,当然,也增加了很多
2)输出层的神经元也可以多个输出,可以有多个输出,这个模型可以灵活地应用于分类的回归,以及机器学习等其他领域维数的聚类,等等。
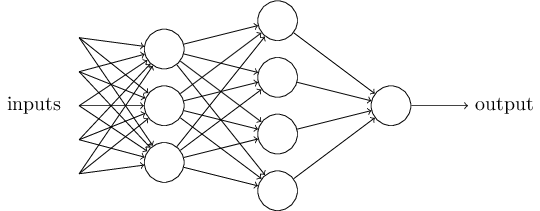
多个输出在输出层神经元对应的实例如下图,输出层神经元现在有四个。3)做扩展激活功能、激活功能的感知器是签署(z)美元美元,虽然简单的处理能力是有限的,所以一般神经网络的激活使用其他功能,例如,我们使用乙状结肠功能在逻辑回归,即:$ $ f(z)= \压裂{ 1 } { 1 + e ^ { z } } $ $。
有成功谢谢softmax ReLU,等等
通过使用不同的激活函数,神经网络的表达能力增强。对各种常用的激活函数,我们专门在后面。在前一节中我们看到的扩张基于感知机神经网络,并且可以被理解为DNN有很多隐层神经网络。
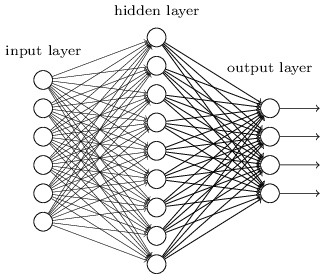
这个很多,没有任何度量DNN多层神经网络和神经网络的深度也指的是一件事,当然,有时被称为DNN多层感知器(多层感知器,MLP),名字是多少。之后我们讨论了神经网络DNN默认情况下。从部门,根据不同层次DNN DNN内部层神经网络可以分为三种类型,输入层、隐藏层和输出层,正如图表的例子,一般来说第一层输出层,最后一层是输出层,中间一层隐藏层。
层与层之间的联系,也就是说,任何一个神经元的第一层与I + 1层的神经元连接吗。
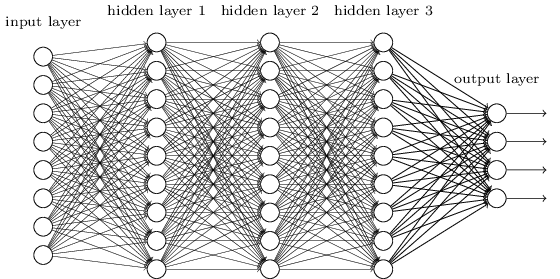
虽然DNN看起来很复杂,但当地的小模型,或和感知机,也就是说,z =美元之间的线性关系总和\限制w_ix_i + b $ $ \σ+一个激活函数(z)美元。因为DNN层多,美国之间的线性关系系数w b美元美元和偏见的数量很多。
DNN的具体参数是如何定义的。首先,让我们看一看的定义系数w美元之间的线性关系?
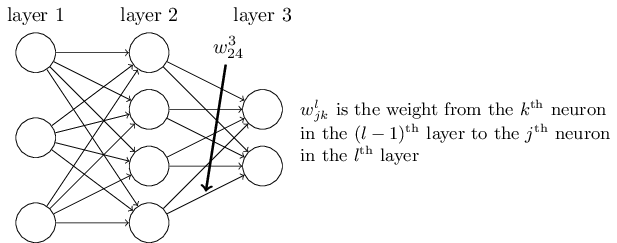
DNN下图三层,第四个神经元的例如,二楼到三楼第二线性系数被定义为美元w_ { 24 } ^ 3美元。上标3 w美元代表线性层系数和相应的下标索引是第三层2的输出和输入指数第二层4。你可能会问,为什么不美元w_ { 42 } ^ 3美元,但美元w_ { 24 } ^ 3美元。主要是为了促进表示,该模型用于矩阵运算,如果美元w_ { 24 } ^ 3美元为每个矩阵w ^和Tx + b,美元转置是必需的?产出指标方面,线性操作不需要转置,即直接$ $ wx + b。总结,第一个l - 1层k美元神经元l层美元第j神经元线性系数被定义为$ w_ jk } { l ^ $。注意,没有w美元参数的输入层。看看偏见b美元的定义。
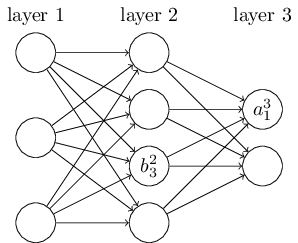
DNN或者三层,例如,二楼第三个神经元的偏见被定义为美元b_3 ^ { 2 } $。其中,上标2代表层,索引下标3代表偏见的神经元。同样,三分之一的第一个神经元偏见应该表示为美元b_1 ^ { 3 } $。同样,输入层没有偏差参数b美元。在最后一节中,我们介绍了各层DNN w美元线性关系系数,偏见b美元的定义。
假设我们选择激活函数\σ(z)美元美元,隐藏层和输出层的输出值一美元,是DNN下面三层,使用的思路和感知机,我们可以使用下一层的输出计算输出,所谓DNN向前传播算法。第二层的输出美元a_1 ^ 2,a?^ 2,a_3 ^ 2美元,我们有:$ $ a_1σ^ 2 = \(z_1 ^ 2)= \σ(w_ { 11 } ^ 2 x_1 + w_ { 12 } ^ 2 x_2 + w_ { 13 } ^ 2 x_3 + b_1 ^ { 2 })$ $ $ $ a?σ^ 2 = \(z_2 ^ 2)= \σ(w_ { 21 } ^ 2 x_1 + w_ {和} ^ 2 x_2 + w_ { 32 } ^ 2 x_3 + b_2 ^ { 2 })$ $ $ $ a_3σ^ 2 = \(z_3 ^ 2)= \σ(w_ { 31 } ^ 2 x_1 + w_ { 32 } ^ 2 x_2 + w_ { 33 } ^ 2 x_3 + b_3 ^ { 2 })$ $。
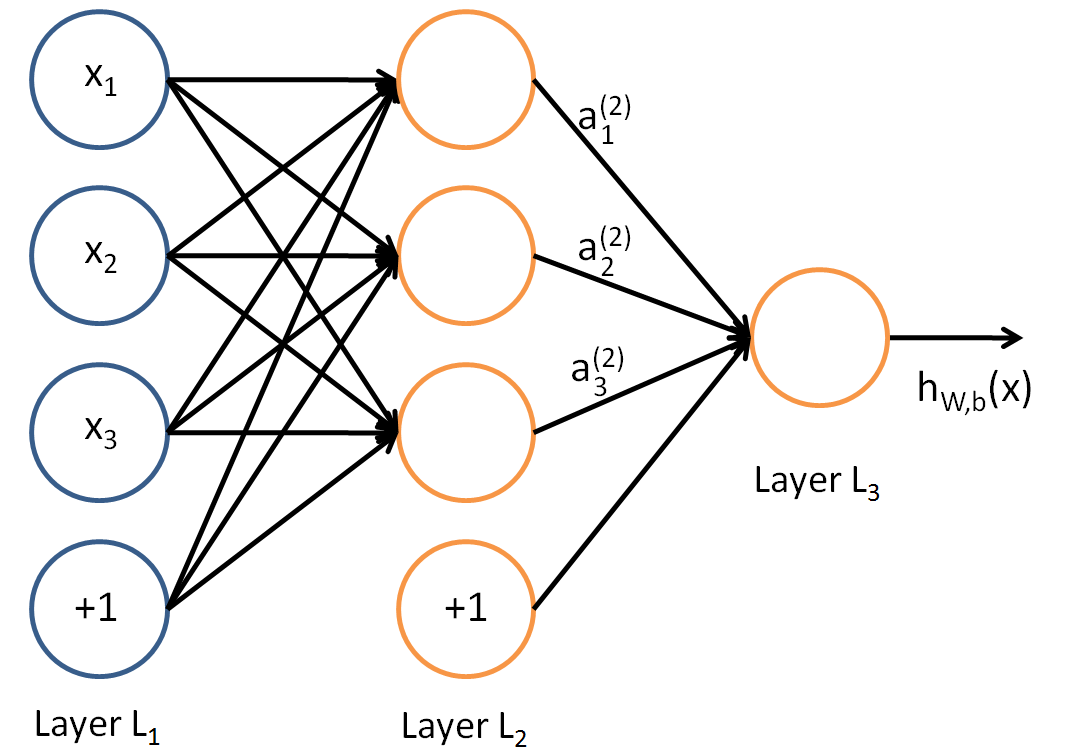
第三层a_1 ^ 3美元的输出,我们有:$ $ a_1 ^ 3 = \σ(z_1 ^ 3)= \σ(w_ { 11 } a_1 ^ 3 ^ 2 + w_ { 12 } a?^ 3 ^ 2 + w_ { 13 } a_3 ^ 3 ^ 2 + b_3 ^ { 3 })$ $
泛化的上面的例子,假设第一$ l - 1层由美元神经元,是第一l层美元第一j神经元输出美元a_j ^ l $,我们有:$ $ a_j ^ l = \σ(z_j ^ l)= \总和σ(\ \ limits_ { k = 1 } ^ mw_ jk } { ^ la_k ^ { 1 } l + b_j ^ $ $ l)
其中,如果l = 2美元,美元a_k ^ 1 xk $ $ $为输入层
从上面可以看出,用代数的方法一个接一个表示输出更为复杂,如果用矩阵法更简洁吗。
假设第一$ l - 1层由美元神经元,而第l层美元,共有n神经元层是第一个l $ $ w美元形成一个线性系数n \乘以m矩阵w美元^ $ $,第l层偏压b美元美元$ n \乘以向量b l ^ 1美元,美元第一$ $ l - 1层的输出向量形成的美元1美元\ * $ $ ^ { 1 } l美元,第l层美元之前激活的线性输出z美元$ n \ z向量乘以1 $ $ ^ { l },美元的输出层形成第一$ l $ $ $ $ n \ * 1 $ $一个向量^ { l } $。表示矩阵法,第一层的输出l:$ $ ^ l = \σ(z ^ l)= W拉^ ^ { 1 } l + b l $ $ ^。这个方法是简洁而美丽的背后,我们的讨论将基于上述矩阵法
上一节数学推导,向前传播算法DNN也变得容易。
所谓DNN向前传播算法是利用我们的几个W美元权重系数矩阵,偏差向量b美元向量和输入值x美元一系列线性运算和激活操作,从输入层,一层又一层的反向计算,一直到操作到输出层,得到的输出值。输入:L总层数,全部隐藏层和输出层相应的矩阵W美元,偏差向量b美元,输入值向量$ $ x。
输出:输出层的输出^ L一美元
1)初始化$ ^ 1 = $ x
2)对l - l = 2美元美元,美元计算:$ $ ^ l = \σ(z ^ l)= W拉^ ^ { 1 } l + b l ^ $ $
最终的结果是输出^ L一美元
看DNN向前传播算法,似乎没有什么效果,这是很多矩阵W美元,偏差向量b美元如何获得相应的参数。
如何得到最优矩阵W美元,偏差向量b美元?这再次当我们谈论DNN反向传播算法?和理解反向传播算法的前提是理解DNN模型和向前传播算法。这就是为什么我们这篇文章。(欢迎转载,转载请注明来源。
欢迎交流:pinard。刘@爱立信。Com)。1)
由迈克尔·尼尔森神经网络和这本书由伊恩·格拉汉姆·古德费勒Yoshua Bengio,亚伦考维尔2)
深度学习深度学习3)
